 Source file : https://github.com/junn279/python_examples/blob/master/crawling.py
Source file : https://github.com/junn279/python_examples/blob/master/crawling.py
예전에 잠깐 영어 공부할 때 틈틈히 들었던 팟케스트로 CNN10 (Student News) 가 있었다. 가끔 어느 날에는 Dr. Sanjay Gupta가 의학에 관련되는 내용을 얘기해줄 때가 있었는데, 당시 재미삼에서 의학 칼럼이 어느날에 방송되었는지 알아두면 쓸모가 있을 것 같았다. 물론 당시 제대로 활용은 못했지만.
개인적인 일들이 마무리가 되었고, 다시금 제대로 대학원 과제를 진행해보고자 python을 세팅하면서 이전에 만들었던 소스가 눈에 띄어, 누군가에게는 혹시 도움이 될까 하여 겸사겸사 포스팅해보고자 한다.
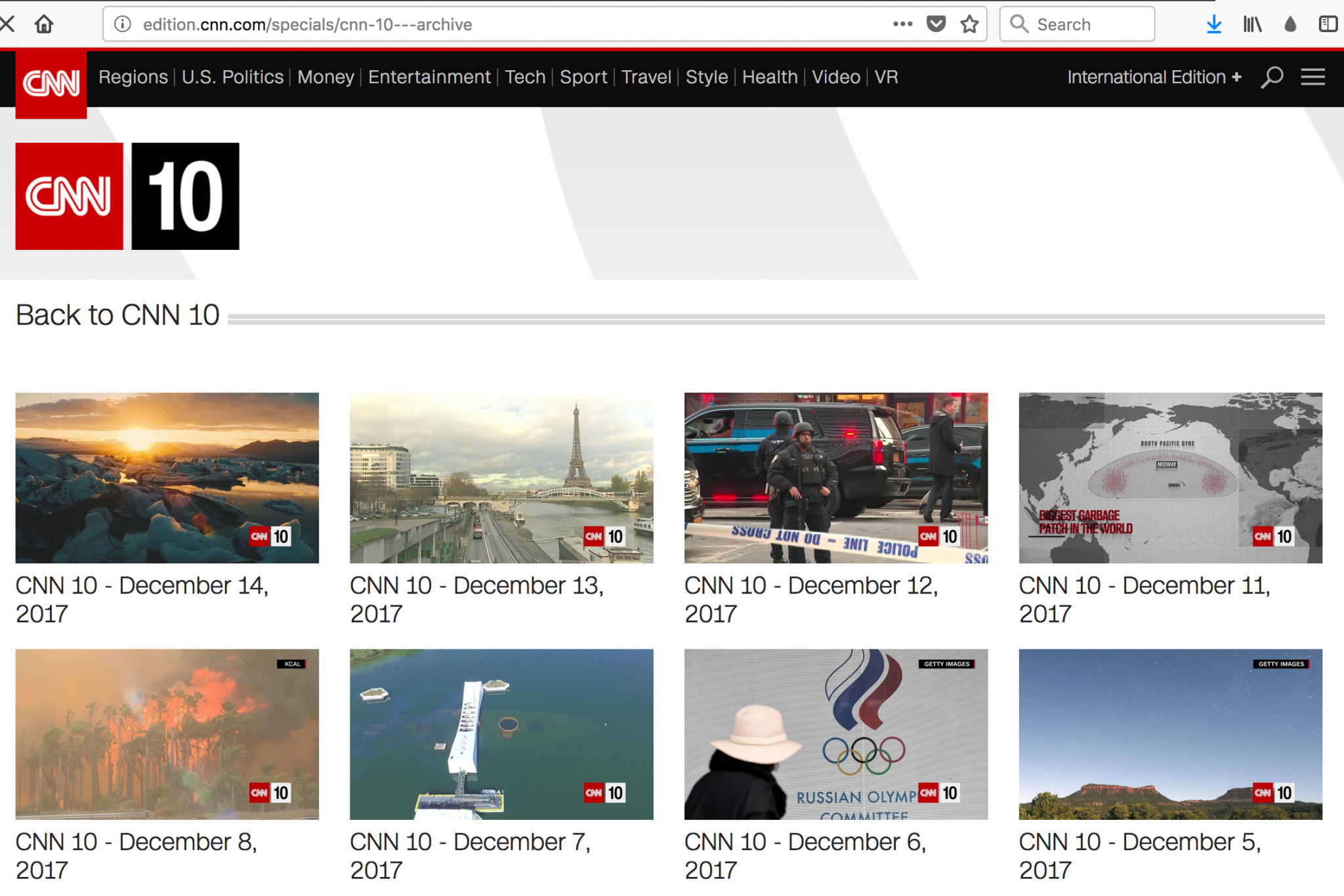
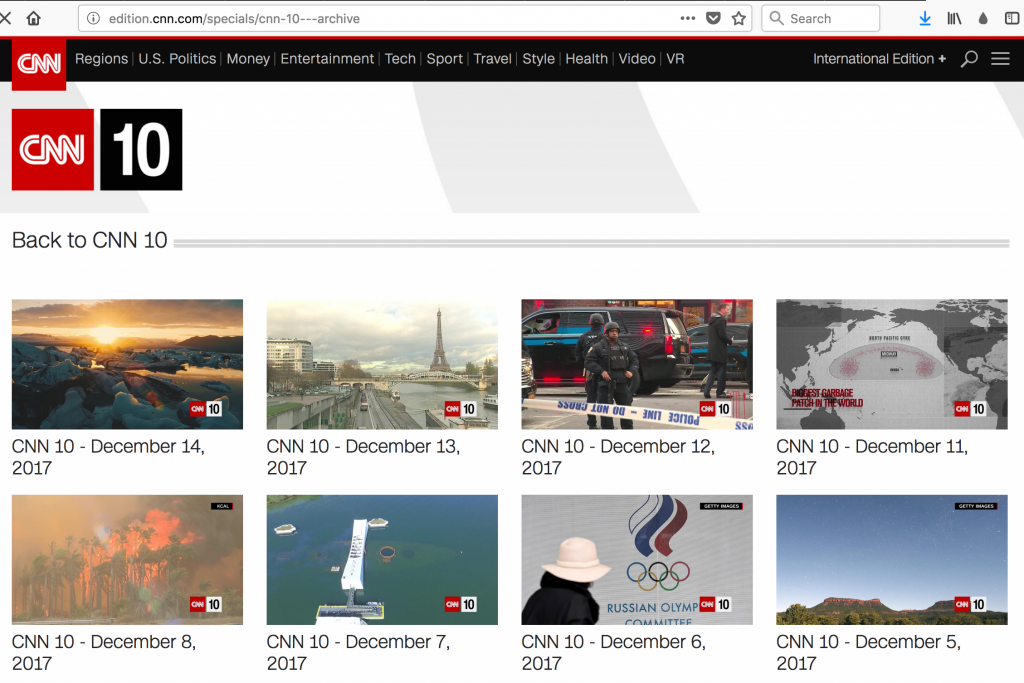
Crawling에서의 핵심은 중복되는 규칙을 먼저 발견해야 한다. 예를들면 위의 CNN10 메인 페이지(http://edition.cnn.com/specials/cnn-10—archive) 의 소스를 살펴보면 각 날짜에 해당하는 Article들이 아래의 태그로 나누어진다.
![]() 다시 정리해보자면
다시 정리해보자면
(2) 제목
(3)
우리가 (2)의 span 태그를 타켓을 한다면, span 바로 위의 a 태그는 ‘parent’라는 객체로 인식이 된다. ..이러한 인식 방식을 DOM 구조라고 하는데, 크롤링을 목표로 하는 입문자가 있다면 이 개념을 어느정도 간단하게나마 체득해놓을 필요가 있다.
예제의 크롤링은 다음과 같이 이루어진다.
- 문서를 가져온다.
- 해당되는 태그를 찾는다.
- 필요한 값들을 가져온다.(attribute, link 등등)
- Link를 통해 다시 각각의 문서를 가져온다.
- Gupta라는 이름이 들어간 문서를 찾는다.
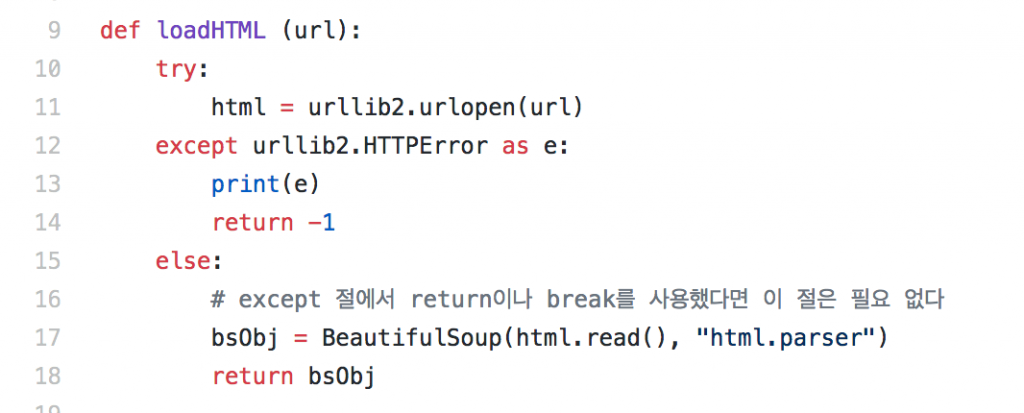
loadHTML을 특정 페이지를 불러서 그것을 BeautifulSoup이라는 객체로 바꾸어 넘겨준다. BeautifulSoup는 위에 말했던 DOM 구조를 쉽게 엑세스하기 위한 일종의 parser라고 생각하면 된다.
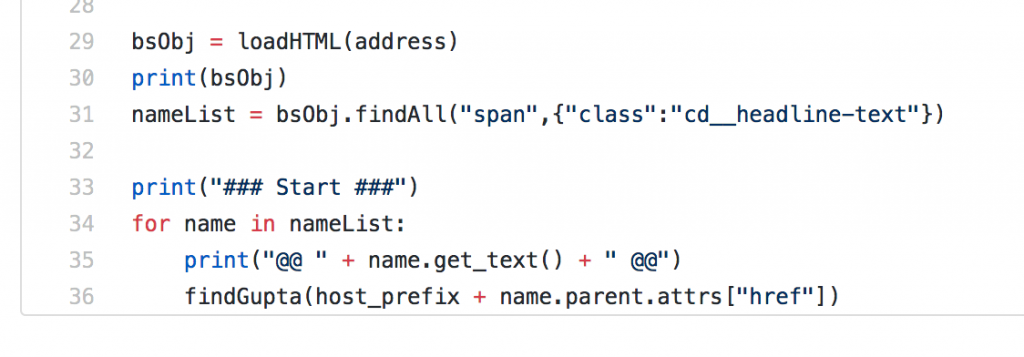 시작은 위에 적었던 CNN10의 첫 페이지(소스를 보면 address 변수로 정의됨)를 읽고, 찾은 규칙에 따라 각 아카이브를 적어둔 태그(span 태그, class이름이 cd__headline-text라고 attribute가 설정되어있다)를 찾고, 그 각 아카이브들을 for-loop를 통해 다시 ‘gupta’ 라는 단어를 찾기 위해 find_gupta라는 함수로 각 아카이브의 주소를 넘기게 된다.
시작은 위에 적었던 CNN10의 첫 페이지(소스를 보면 address 변수로 정의됨)를 읽고, 찾은 규칙에 따라 각 아카이브를 적어둔 태그(span 태그, class이름이 cd__headline-text라고 attribute가 설정되어있다)를 찾고, 그 각 아카이브들을 for-loop를 통해 다시 ‘gupta’ 라는 단어를 찾기 위해 find_gupta라는 함수로 각 아카이브의 주소를 넘기게 된다.
들어가보면 알겠지만 각각의 아카이브(archive,article)은 결국 뉴스의 영어 대본이다.
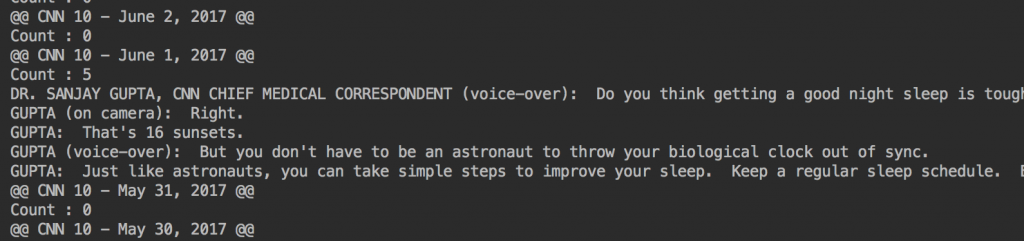
findGupta라는 함수를 보면 다시금 저 대본페이지(아카이브)를 BeautifulSoup 객체로 받아서 본문에 해당하는
그리고 정규표현식을 이용해 Gupta (대소문자 모두 가능)한 단어를 찾아서 그것이 발견되면 출력해주도록 했다.

중단 시점은 따로 넣어두지 않아 강제로 멈추어야 한다. (archive가 거의 2015년 전으로 더 가야지 되기 때문에 꽤 상당한 시간이 소요된다)
간만에 예제를 돌려봤더니, 올해 여름을 기점으로 Dr. Gupta가 더이상 등장을 하지 않았던 것 같다.
저작권 문제만 없었다면, 해당 클립만 잘라서 대본이랑 같이 의학 뉴스 동영상 모음 같은것 만들어보고 싶은데 아쉽다.