제 첫 deep learning 연구를 아카이브에 올렸습니다.
들어가기에 앞서
이글의 원문은 2017년 4월 23일, Dhruv Parthasarathy가 작성한 A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN 입니다.
원작자의 허락을 받고 번역하였음을 미리 밝힙니다.
글의 원활한 이해를 이해 저자(Dhruv Parthasarathy) 및 그 팀원을 ‘나, 우리’로 표기하였습니다.
2017년 4월 글이기에 본문에 ‘최신’이라고 적혀있는 문구는 이미 1년이 지난 시점임을 미리 이해하시길 바랍니다.
Athelas 에서 우리의 팀은 합성곱 신경망(Convolutional Neural Networks;이하 CNN)을 이용해 단순한 분류(classification) 이상의 것들을 구현할 수 있었다. 이 포스팅에서 CNN이 이미지의 segmentation에 어떻게 이용될 수 있었는지 보여주고자 한다.
========
2012년 ImageNet 에서 Alex Krizhevsky, Geoff Hinton 와 Ilya Sutskever 가 우승(https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks)을 한 이래로 CNN은 이미지 분류에 있어서 표준 처럼 되어버렸다. 그 이후로도 CNN은 계속 발전하였고, ImageNet Challenge 에서는 사람이 직접 분류한 결과보다 더 뛰어난 수준에 이르렀다.
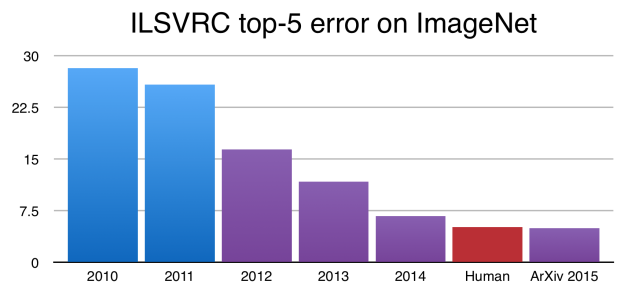
이 결과들은 인상적임에는 틀림없지만, 신경망에서 classification은 아직 사람이 시각적으로 이해하는 과정의 복잡함과 다양함에 비해 꽤 단순한 수준이다.

이미지 분류(classification)는 일반적으로 하나의 객체가 그려져 있는 이미지가 있을 때 이 객체가 무엇인지 알아내는 것이다. 그러나 실제 환경에서 사람이 주위를 둘러싼 세상을 바라보고 인식할 때 상당히 복잡한 과정을 요하게 된다.

우리는 많은 겹쳐져 있는 대상들과 이들 뒤의 배경으로 구성된 복잡한 광경을 보고, 단순히 그 각각의 것들을 분류(classify)할 뿐 아니라 그 대상들의 경계를 나누는-즉 서로의 관계를 식별(identify)-과정을 해낼 수 있다

CNN이 우리를 돕기 위해 이러한 복잡한 과정을 해낼 수 있을까? 다시 말해서 더 복잡한 이미지가 주어졌을 때, 우리는 CNN을 통해 각각의 객체를 식별하고 그 경계를 구분해낼 수 있을까? Ross Girshick 과 그의 동료들이 몇년간 보여주었던 것 같이 대답은 결과적으로 Yes 다.
이 글의 목표
이 포스팅을 통해, 이미지에서 객체 검출(detection)과 분할(segmentation)에 사용되는 주요 테크닉의 배경에 대한 직관을 갖출 수 있도록 하고, 어떻게 다른 연구자들이 그 전의 성과로부터 그 다음 결과로 발전해 나갔는지를 볼 것이다. 특히 우리는 이 문제에 먼저 이용되었던 R-CNN(regional CNN)을 보고, 그 다음 세대인 Fast R-CNN, Faster R-CNN을 살펴볼 것이다. 마지막으로 우리는 최근(역자주: 글이 작성되었던 2017년 4월 기준) 페이스북 연구팀에서 발표한, pixel 수준의 segmentation을 해낸 Mark R-CNN 을 살펴볼 것이다. 아래 논문들을 참조하였다.
- R-CNN: https://arxiv.org/abs/1311.2524
- Fast R-CNN: https://arxiv.org/abs/1504.08083
- Faster R-CNN: https://arxiv.org/abs/1506.01497
- Mask R-CNN: https://arxiv.org/abs/1703.06870
=================
2014: R-CNN – 객체 검출(object detection) 과정에 초기에 사용되었던 모델

UC Berkeley의 Jitendra Malik 교수가 이끄는 작은 팀은, University of Toronto의 Hinton 팀의 연구에서 영감을 얻은 뒤 그들 스스로 질문을 하나 하였는데 지금에 와서는 필연적으로 보이는 것이었다.
Krizhevsky 등이 발표한 연구로 어느 정도까지 객체를 검출(detection)을 일반화 시킬 수 있을까?
객체 검출(detection)이란 위의 그림과 같이, 이미지에서 다른 객체들을 찾고 그들을 분류(classify)하는 것을 말한다. Ross Girshick (이 이름은 다시 한번 나올 예정이다), Jeff Donahue와 Trevor Darrel로 구성된 팀은 ImageNet과 유사한 PASCAL VOC 대회(Visual Object Classes Challenge) 에서 Krizhevsky의 연구 결과를 이용해 이 문제를 풀었다.
저자들은 서술하기로,
이 논문은 CNN이 PASCAL VOC 대회에서 다른 HOG-like feature(역자주: histogram of oriented gradients 를 이용해 객체를 찾기위해 사용하던 알고리즘, feature를 찾는 방식이다)를 이용한 검출 방식에 비해 객체 탐색(object detection)에 있어 극적으로 높은 수준의 성능을 이끌어낼 수 있다는 것을 처음으로 보였다
여기서 잠시 R-CNN(Regions with CNNs)의 구조(architecture) 를 이해하고 진행하겠다.
R-CNN에 대한 이해
R-CNN의 목표는 하나의 이미지에서 주요 객체들을 박스(Bounding box)로 표현하여 정확히 식별(identify)하는 것에 있다.
Input: 이미지
Outputs: 박스로 영역 표시(Bouding box) + 각 객체에 대한 라벨링(class label)
어떻게 박스의 위치를 찾아낼 수 있을까? R-CNN은 우리가 직관적으로 생각하는 것과 같이 해낸다. 그것은 무수히 많은 박스들을 생각한 다음에 그 중에 어떤 것이든 실제 객체에 해당하는 것을 찾는 방식이다.

R-CNN은 Selective search를 통해 이 상자들, 또는 region proposal라고 불리는 영역을 생성해낸다. Selective search는 위의 사진에서 보는 것과 같이 다양한 크기의 창(window)을 만들어 내는데, 이 창은 비슷한 질감이나 색, 강도를 갖고 있는 인접한 픽셀들로 구성된다. Selective search에 대해서는 여기(http://www.cs.cornell.edu/courses/cs7670/2014sp/slides/VisionSeminar14.pdf)를 읽어보면 된다.
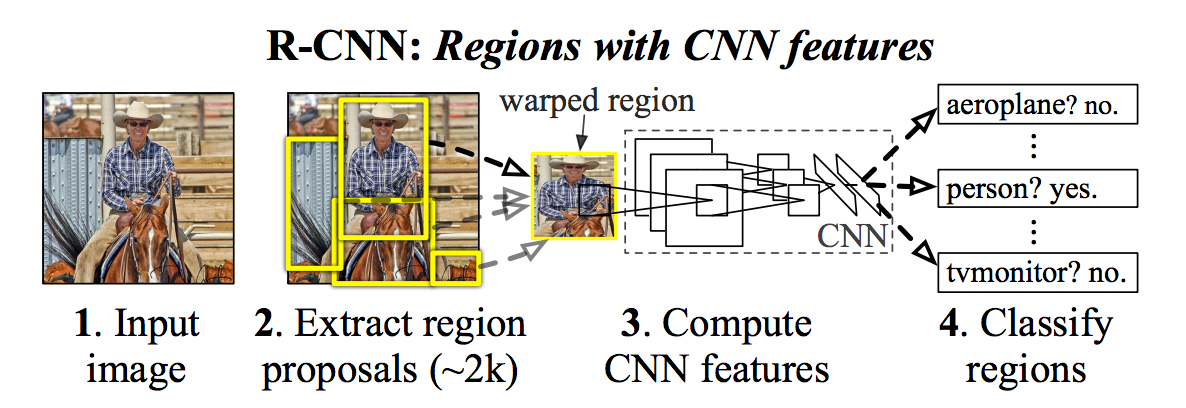
일단, 이 영역들이 생성되면, R-CNN은 이 영역을 적절히 찌부러뜨려(warp) 모델에 표준화된 크기(역자주: 입력값으로 지정된 이미지 사이즈)로 만들어낸다. 그리고 AlexNet (2012년 ImageNet 에서 우승했고 R-CNN에 영감을 주었던 모델)을 개량한 모델에 위의 그림과 같이 통과시킨다.
R-CNN은 이 모델의 마지막 층(layer)에 서포트 벡터 머신(SVM)을 두어 간단하게 이 결과가 객체인지 아닌지, 객체가 맞다면 어떤 객체인지를 분류하도록 하였다. 이는 위 그림의 4번에 표시되어있다. (역자주: 지금의 지식으로는 왜 Softmax를 쓰지 않지? 라고 질문할 수 있다. 그리고 실제로 이후 Softmax로 바뀐 알고리즘이 나온다)
Bounding Box 개선하기
객체를 찾아 박스안에 두었는데, 이 때 우리는 실제 객체에 딱 맞춰 박스를 그려낼 수 있을까? 물론 가능하다. 그리고 이것은 R-CNN의 마지막 단계가 된다. R-CNN은 마지막 결과를 만들어 내기 위해 더 tight한 box를 만들어내는데, 이 때 단순한 linear regression을 이용한다. 그 선형 회귀식의 입력과 결과물은 다음과 같다.
입력 : 객체에 해당하는 이미지의 부분(sub-region)
출력 : 그 입력 부분(sub-region)에 맞는 새로운 bounding box의 좌표들
요약하자면, R-CNN은 다음의 단계를 거친다.
1. 인식을 시킬 대상이 될 만한 객체를 담는 Bounding boxes 세트를 만든다.
2. Pre-trained AlexNet에 각각의 box들을 넣어본다. 그리고 SVM을 통해 각 박스가 어떤 객체인지 인식시킨다.
3. 객체가 인식되면 이 box를 linear regression model을 통해 딱 맞추도록(tighter coordinates) 한다.
=======
2015: Fast R-CNN – 빨라진 속도와 심플해진 R-CNN

R-CNN은 잘 작동했지만, 몇가지 이유로 꽤 느렸다:
- 매번 하나 이미지에서 나오는 모든 각각의 제안된 영역을 각각 CNN(AlexNet)을 통과시켜야 하는데, 이는 하나의 이미지당 2000번의 forward pass를 거쳐야 한다는 이야기이다.
- 3개의 다른 모델을 학습시켜야 했다. Image feature를 생성하는 것, classifier가 class를 예측하는 것, regression model이 bouding box를 찾아낸 것. 이것이 전체적인 pipeline을 학습시키 어렵게 하였다.
2015년 R-CNN의 제 1저자였던 Ross Girshick은 이러한 문제들을 해결하여, 이 짧은 이야기의 두 번째 알고리즘인 Fast R-CNN을 발표하였다. 그 주요 insight를 살펴보겠다.
Fast R-CNN Insight 1: RoI (Region of Interest) 풀링
CNN의 forward pass에 대해 Girshick가 깨달은 것은, 하나의 이미지에는 많은 수의 proposed regions이 있는데 이 영역들에는 항상 겹쳐진(overlapped) 영역들이 존재하고, 이것들이 계속되는 계산을(약 2000번에 가까운) 유발한다는 것이었다. 그의 생각은 단순했다-CNN을 한 이미지에 딱 한번만 돌리고, 2000번에 이르는 제안(proposal)들에 대해 나눠서 모델에 넣지 않고, 계산된 값들을 공유하는 방법을 찾을 수 있지 않을까?
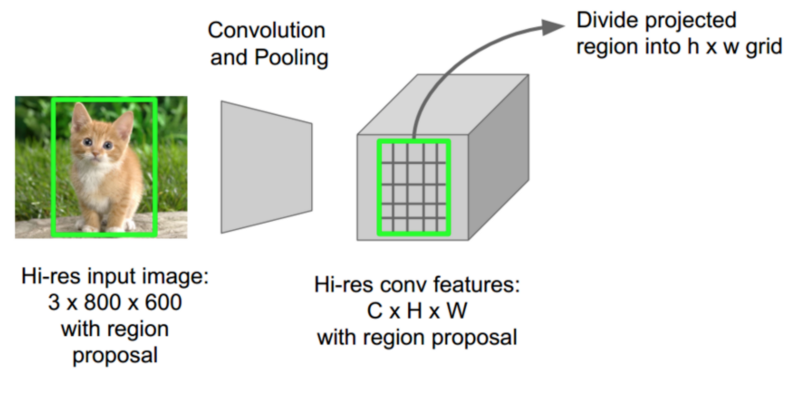
Fast R-CNN이 하는 일이란 정확히 RoIPool(Region of Interest Pooling)이라고 알려진 테크닉으로 이루어 내는 것이다. RoIPool의 핵심은 한 이미지의 subregion에 대한 forward pass값을 서로 공유하는 것이다. 위의 그림을 통해 어떻게 각 region에 대한 CNN feature가 feature map의 동일한 영역으로 부터 선택되어 값을 얻어내는지 확인할 수 있다. (역자 주: 사실 그림만으로는 설명이 빈약하다. https://github.com/deepsense-ai/roi-pooling에서 추가적인 이해에 도움을 얻을 수 있다) 그리고 나서 각 영역의 features들은 풀링을 거친다(주로 max pooling). 결국 우리에게 주어지는 것은 단 하나의 pass일 뿐이다.(2000개와 비교해보라)
Fast R-CNN Insight 2: 모든 모델을 하나의 네트워크로
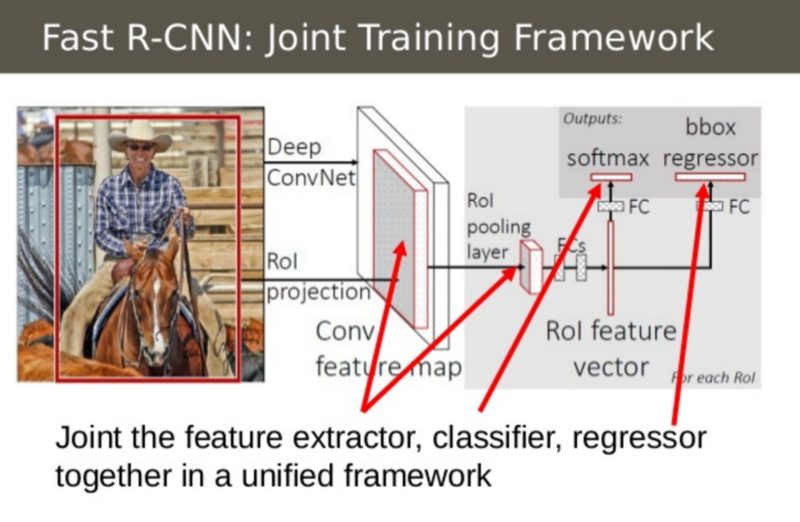
두번째 생각은 세개의 모델을 하나의 네트워크로 구성하는 것이다. 이전의 R-CNN은 image feature를 추출(CNN)하고 분류하는 모델(SVM), 그리고 bounding box를 맞추는 것(regressor)를 나누었다. Fast R-CNN은 대신에 하나의 네트워크로 모든 세가지를 계산하였다.
위의 그림을 보면 이를 어떻게 구현했는지 알 수 있다. Fast R-CNN은 SVM classifier를 top layer에 softmax layer를 둠으로써 CNN의 결과를 class로 출력하게 했다. 또한 box regression layer를 softmax layer에 평행하게 둠으로써 bounding box 좌표들을 출력하게 했다. 이러한 방식으로 모든 필요한 결과물을 하나의 네트워크로 구할 수 있는 것이다!
Inputs: region proposal이 된 이미지들
Outputs: 각 region에 있는 객체의 class들과 그에 따른 tighter bounding box들
=================
2016: Faster R-CNN – 속도를 높인 영역 제안(region proposal)
위의 성과에도 불구하고, 하나의 남은 병목지점(bottleneck)이 Fast R-CNN 과정 중에 있었다. 그것은 region proposer였다. 우리가 봤듯이 객체의 위치를 찾는 과정에의 첫 번째 과정은 바로 ‘다양한, 가능성 있는’ bounding box들 또는 region of interest(ROI)들을 생성하는 과정 이었다. Fast R-CNN에서, 이러한 제안들은 Selective Search라는 꽤 느린 과정을 거치는데, 이 과정이 모든 흐름에 있어서 병목현상을 만들어낸다.

2015년 중반, Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun로 구성된 Microsoft Research 팀은 region proposal 단계를 거의 지체없이 해낼 수 있는(cost free) 발견했는데, 그들은 그 이름을 (창의적이게도) Faster R-CNN 이라고 하였다.
Faster R-CNN의 아이디어는 각 이미지에서 classification의 첫 단계인 CNN의 forward pass 를 통해 얻어진 feature들에 기반하여 영역을 제안하는 것이었다. 즉, CNN결과를 selective search 알고리즘 대신 region proposal에 이용해보는 것이 어떨까? 라는 질문이었다.
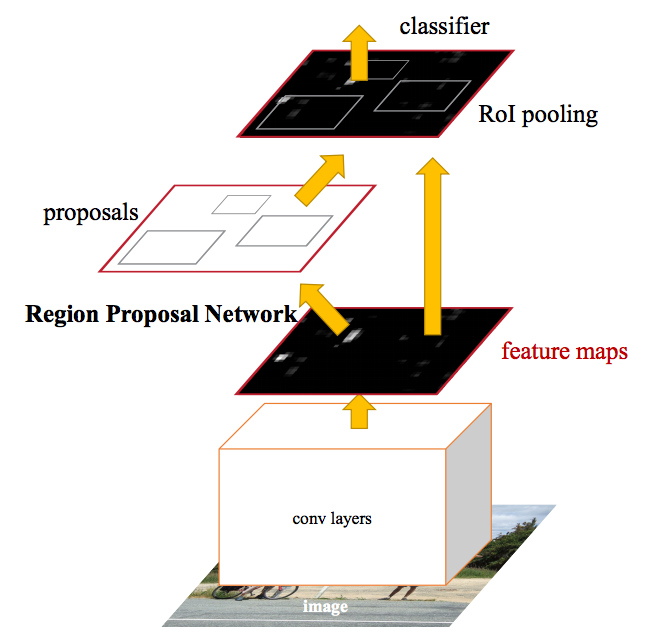
실제로, 이것이 곧 Faster R-CNN 팀이 이루어 낸 결과였다. 위의 그림을 보면, 어떻게 single CNN이 region proposal과 classification을 동시에 해냈는지 볼 수 있다.(역자주: 방법론은 아래에 다시 나온다.) 이러한 방법으로, 단지 하나의 CNN만 학습시키면 region proposal은 거저 얻을 수 있다! 저자는 다음과 같이 적었다:
우리의 발견은, region-based detector를 이용하여 얻은 convolutional feature map이 Fast R-CNN 처럼 region proposal에 이용될 수 있다는 것이다.(따라서 cost-free region proposal이 가능하다)
따라서 input과 output은 다음과 같다.
Input: 이미지들(region proposal이 필요하지 않다)
Output: 분류(classification) 및 이미지 내부 객체들의 bounding box 좌표
어떻게 영역이 생성되는가?
Faster R-CNN이 어떻게 CNN feature로 부터 region proposal을 해냈는지 볼 차례다. Faster R-CNN은 Fully Convolutional Network 을 CNN이 만들어낸 feature들의 맨 위(top layer)에 놓았는데, 이것이 Region Proposal Network 이라는 것이다.
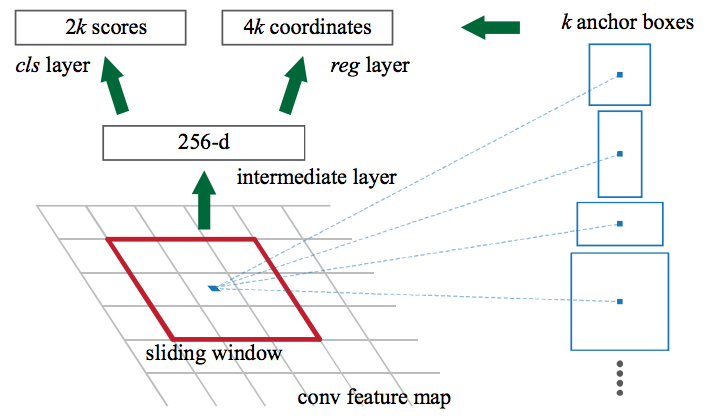
Region Proposal Network은 sliding window를 CNN feature map 을 지나하게 하면서, 각 윈도우에서 k 개의 가능성있는 bouding box와 이 박스들의 기대값(역자주: 일종의 객체 인식률)을 출력해준다. 이 k 개의 박스들은 무엇을 나타내는가?

{kind=link}
직관적으로, 우리는 이미지에 있는 객체들이 어떤 일반적인 비율과 크기를 갖을 것이라고 생각할 수 있다. 예를 들어 사람의 형상을 닮은 사각형들을 떠올려 볼 수 있다. 우리는 아마 이것이 매우 매우 얇을 것이라고 생각하지는 않을 것이다. 이러한 방식으로 k 개의 일반적인 비율(common aspect ratio)을 지닌 anchor box 로 이름 붙이고 고안하였다. 각각의 anchor box를 이용하여 우리는 하나의 bounding box 및 score를 이미지의 위치별로 출력해냈다.
Anchor box를 생각하면서, 이 Regional Proposal Network의 입력과 출력들을 보자.
Input: CNN feature map.
Output: 앵커당 하나의 bounding box 와 스코어(이것은 얼마나 이 bounding box 내의 이미지가 실제 객체일지를 나타낸다.)
그리고 나서 우리는 이런 객체일 것 같은 bounding box 을 Fast R-CNN으로 넣어 classification과 tightened bounding box를 구한다.
============
2017: Mask R-CNN – 픽셀 수준의 segmentation까지 Faster R-CNN을 확장시키다.

지금까지는 우리는 bounding box를 이용해서 다른 객체들의 위치를 효과적으로 얻어내는데 CNN feature를 다양한 흥미로운 방식으로 사용할 수 있음을 볼 수 있었다.
우리가 한걸음 더 나아가기 위해 이 기술을 확장시켜, 단지 바운딩박스 뿐 아니라 정확한 픽셀의 위치까지 파악할 수 있을까? Facebook AI의 Kaiming He 및 Girshick이 포함되어있는 연구자들은 Mask R-CNN이라는 아키텍쳐를 이용하여 확인해보았다.

Fast R-CNN, Faster R-CNN과 같이, Mask R-CNN의 기저에 있는 생각은 꽤 단순하다. Faster R-CNN이 object detection을 꽤 잘 해냈던 것을 고려한다면, 그것을 pixel level segmentation을 해내는데 까지 확장시킬 수 있지 않을까?
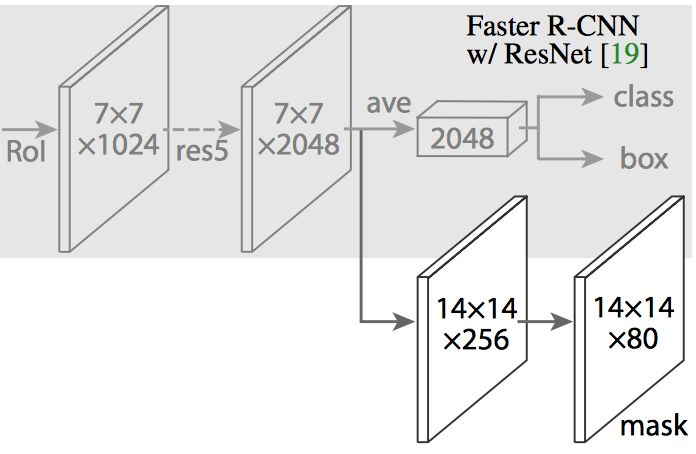
Mask R-CNN은 Faster R-CNN의 branch를 두어 주어진 픽셀이 그 객체의 일부인지 판별하는 binary mask를 출력하는데 사용하였다. (위 그림의 흰색으로 그려진) 그 branch는 그 직전의 레이어와 같이 FCN으로 CNN based feature map의 상단에 놓여진다. 입력과 출력은 다음과 같다.
Input: CNN Feature map
Output: 1,0으로 이루어진 행렬, 1은 그 픽셀이 객체에 포함되는 경우, 0은 아닌 경우로 binary mask로 불린다.
여기서 Mast R-CNN의 저자들은 작은 조정을 통해 이 파이프라인이 예상한 대로 작동하도록 만들었다.
RoiAlign – RoIPool을 더 정확하게 다시 정렬하는 방법
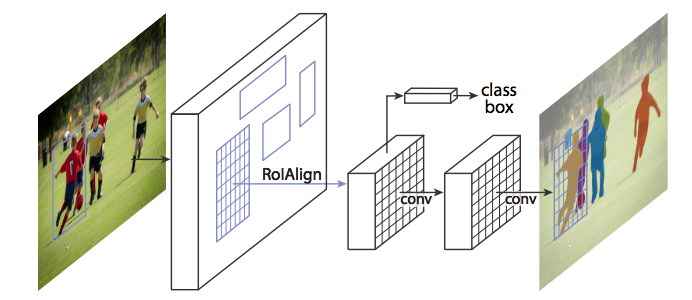
Mask R-CNN의 저자들은 Faster R-CNN의 원래 구조를 변화시키지 않고 실행하였을 때, RoIPool을 통해 선택된 feature map은 원래 이미지의 영역으로부터 약간 잘못 정렬(misaligned)되어있는 것을 확인하였다. Image Segmentation은 Bounding box와 다르게 픽셀 수준의 특이도를 요구하기 때문에 잘못된 정렬은 필연적으로 부정확함을 만들어 낼 수 밖에 없었다.
저자들은 RoIAlign으로 부르는 방법을 통해 RoIPool을 현명하게 조정하여 정확한 정렬을 이룸으로써 이 문제를 풀 수 있었다.
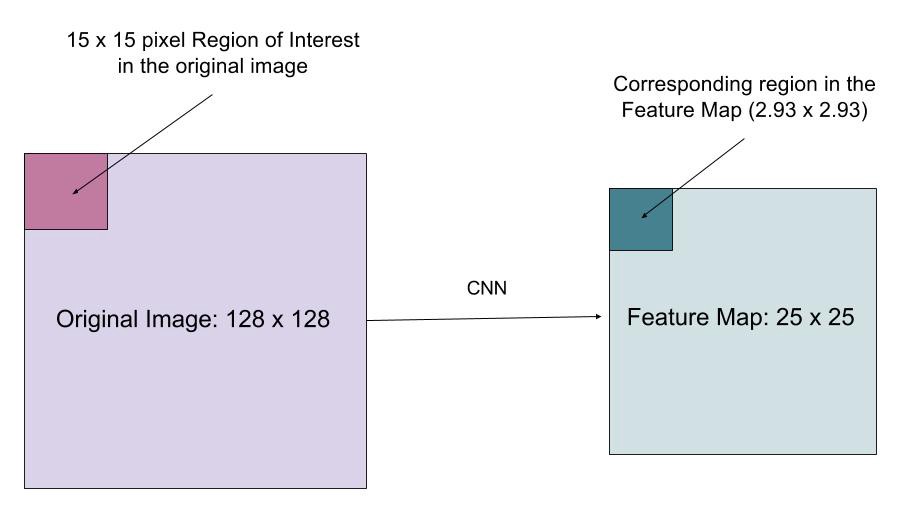
우리가 128×128 크기의 이미지가 있고, feature 맵의 크기는 25×25라고 가정해보자. 그리고 위 그림과 같이 우리가 원본 이미지 좌측 상단의 15×15 픽셀의 영역에 상응하는 feature를 원한다고 가정한다. 우리를 어떻게 이 것을 feature map으로 부터 선택할 수 있을까?
우리는 각 feature map의 픽셀이 원본 이미지에 대해 25/128의 비율로 대응된 다는 것을 안다. 15 픽셀을 원본으로 부터 선택하면, 우리는 15 * 25/128, 즉 2.93 픽셀을 선택하게 된다.
RoIPool에서 우리는 이 2.93에서 소수점을 버리고 2픽셀을 선택하게 되는데, 이는 약간의 misalignment를 유발한다. 그러나 RoIAlign에서 우리는 이러한 버림을 회피하게 된다. 대신, 우리는 bilinear interpolation(https://en.wikipedia.org/wiki/Bilinear_interpolation) 의 이라는 것을 사용하여 2.93 이라는 숫자가 의미할지 정확히 파악하게 된다. 높은 수준으로 이것은 우리를 RoIPool로 인해 생기는 misalignment로 부터 해방시켜준다.
일단 mask들이 생성되면, Mask R-CNN은 Faster R-CNN으로 부터 생성된 classification과 bounding boxes 들과 합쳐져 아래와 같은 멋있고 정확한 segmentation을 보여준다:

=====
Repositories (source code)
만약 당신이 스스로 알고리즘을 실행해보기 원한다면, 아래의 관련 있는 repository들을 살펴볼 것
- Faster R-CNN
- Caffe: https://github.com/rbgirshick/py-faster-rcnn
- PyTorch: https://github.com/longcw/faster_rcnn_pytorch
- MatLab: https://github.com/ShaoqingRen/faster_rcnn
- Mask R-CNN
- PyTorch: https://github.com/felixgwu/mask_rcnn_pytorch
- TensorFlow: https://github.com/CharlesShang/FastMaskRCNN
=====
기대하는 것
단 3년이라는 시간동안 Krizhevsky 등 의 R-CNN 으로부터 Mask R-CNN이라는 강력한 결과물에 이르기까지 우리는 연구 커뮤니티가 어떻게 발전해왔는지 보았다. 작게 보면 Mask R-CNN과 같은 결과는 도달할 수 없을 것 같던 놀라운 도약과도 같다. 그러나 이 포스트를 통해, 이러한 발전은 여러 직관들의 합으로 이루어져 있으며, 수년간의 고된 연구와 협업의 결과라는 것을 독자들이 느꼈기를 희망한다. R-CNN, Fast R-CNN, Faster R-CNN 그리고 마지막의 Mast R-CNN을 통해 제안된 각각의 아이디어들은 분명 quantum leap 가 아니었으나, 그것들이 합쳐져 만들어진 성과는 실로 놀라운 결과를 우리에게 보여주었고, 시각적인 정보에 대해 사람 수준의 이해에 더 가까이 갈 수 있도록 해주었다.
나를 특별히 흥분시켰던 것은, R-CNN과 Mast R-CNN 사이의 시간이 단 3년 뿐이었다는 것이다! 지속적인 투자와 집중, 지원이 계속되었을 때, 앞으로 3년 뒤에는 얼마나 더 많이 발전할까?
======
만약 이 글에 대한 오류나 이슈가 있을 경우, dhruv@getathelas.com 메일을 통해 컨택해주길 바란다. 즉각적으로 교정하도록 하겠다.
(역자: 번역된 글에 대해서는 junn279@gmail.com)
만약 이러한 테크닉을 적용하는데 관심이 있다면, 혈액학적 진단에 Computer vision 기술을 이용하고 있는 Athelas 로 와서 우리와 함께 하자.
번역 후기
이 글을 2017년 4월에 작성되었던 포스트로, 처음 본 것은 딥러닝이라는 것에 대해 제대로 공부를 시작하게 되었던 올해 1월 정도 였었다. 물론 이 글로부터 1년이 지난 지금, SSD, YOLO 등의 더욱 fancy하고 빠른 기술들이 발표되었다. 그러나 이 포스팅은 그 근본이 되는 아이디어가 어떻게 흘러왔는지 이해하게 해주는 너무 좋은 글이었고, 누군가 처음 같은 분야에 대해 공부를 하는 사람들에게도 너무 좋은 입문서와 같아, 3월에 저자에게 직접 메일을 보내 한글 번역에 대한 허락을 구하여 진행하였다.
글 자체가 어렵지는 않았으나, 실제로 모든 코드를 직접 열어보고 이해하는 시간이 필요하였기에, 번역의 진행이 생각보다 느렸다. 모든 코드를 직접 짜보지는 못했고, 어느 부분은 그냥 머리로만 이해하였기에 아쉬운 감이 없지 않지만, 그래도 짧은 시간동안 많은 부분에 아이디어를 얻을 수 있었다. (물론 그 구현은 또 다른 이야기겠지만)
다음 포스팅은 아마 SSD나 YOLO와 같은 이 다음 버전들에 대한 이야기, 그리고 음성 합성에 대한 Tacotron 등의 주제로 진행되지 않을까 싶다. 더불어 내 연구 주제들도 어느정도 가시적인 성과가 있을 때 그 내용들도 한번 써보고 싶다.
2018.4.15.
원문 링크 : A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN
17 comments
잘 보고 갑니다!
좋은내용 감사합니다.!!
안녕하세요~
좋은글 잘 읽었습니다~ 감사합니다~
죄송하지만 한기지만 여쭤봐도 될까요~?ㅎㅎ;;;
Mask RCNN의 경우 custom 모델 생성을 위해
Training 데이터의 형태가
원본 이미지 + Mask 이미지 + bounding box(좌표) + label
요렇게 입력이 들어가야 하는건가요?
해당 Github에 가시면 예제가 잘 나와있어서 소스만 잘 분석하시면 되는데요,
최종적으로는 이미지 + label 정보가 들어간 Mask 배열만 들어갑니다.
예를 들면, 400×400 그림에 object가 4개가 있어서 각각 id를 1,2,3,4 이라고 합니다.(0은 배경으로 쓰임)
그럼 입력값은 1. 이미지 400x400x3 (rgb) , 2. 마스크 400x400x4 (object 갯수)
각각의 마스크는 0과 1이 아닌 자신의 id로 값이 구성됩니다. 만약 동일한 객체가 두개라면, id는 1,2,2,3 일테고,
400x400x4 에서 한 마스크는 0,1로 구성, 두 마스크는 0,2로, 마지막 마스크는 0,3으로 구성되는 것이지요.
즉 마스크의 array를 통해 bounding box, label 정보가 모두 들어가게됩니다.
이해가 되셨는지요;;
몇주내로 제가 최근에 발표한 내용을 논문화하면서 깃헙에 올릴 예정이라 그 때 또 한번 확인해보실 수 있으실 것입니다.
친절한 답변 감사드립니다~
소스 분석 해야하는데 급 궁금해져서요 ㅎㅎㅎ;;;
앞으로 올리실 자료 기대하겠습니다~
감사합니다~ㅎㅎ
아….그럼 pre-trained 모델이 아닌 custom 모델을 생성하려면
detection할떄 사각형 영역지정 하는거와 마찬가지로 원본 이미지에 대한 각 object들의 mask 이미지(배열)를 만들어서 넣어줘야 하겠군요……ㄷㄷㄷ
마스크를 만들어내는건 예제에 보면 좌표값을 이용해서 polygon 함수를 이용해서 마스크를 간단하게 만들어냅니다. 레이블링 툴을 이용해서 좌표값만 저장하고, 그걸 마스크로 등록할 때 이용하는 방식으로 하면 그나마 간단합니다.
네네 그런거 같더라구요 ㅎㅎ
답변 감사드립니다~ㅎㅎ
이포스트를 보니 정리가 더 잘되는 느낌입니다 감사합니다~
이제막 이쪽 공부를 시작했는데,,뭔가 다 해 놓은 느낌이 드는건 왜일까요?^^
정리를 잘 해주셔서 감사합니다. 올려주신 논문과 코드들 분석해봐야겠습니다.
네, 이미 너무 많이 발전해버린듯한 느낌이 없지 않죠ㅎㅎ따라잡기도 쉽지않은 요즘입니다.
정말 도움이 많이 되었습니다.
감사합니다!!
감사합니다~
참고하여 공부하는데 정말 좋은 자료네요! 감사합니다~