
‘일본어를 분석하라’
내가 왜 이걸 하고 있지? 라고 생각하고 있을 때면 이미 하고 있다..
Mediteam 사이트의 ‘관련글 찾기’ 알고리즘을 TF-IDF를 이용해 구하고 이를 Cosine similarity를 이용해서 유서성을 구현하여 실제 사이트에 올려보았다. (아래 포스팅 참조)
참고:
Mediteam.us 개발 – nodeJS와 python 상호 간 통신(using python-shell, synchronize)
———————-
그렇게해서 완성한 결과 아래와 상태처럼 출력해낼 수 있었다.
(2018.1.5 현재, 일부 포스트에서만 보임, 조만간 바뀔 예정)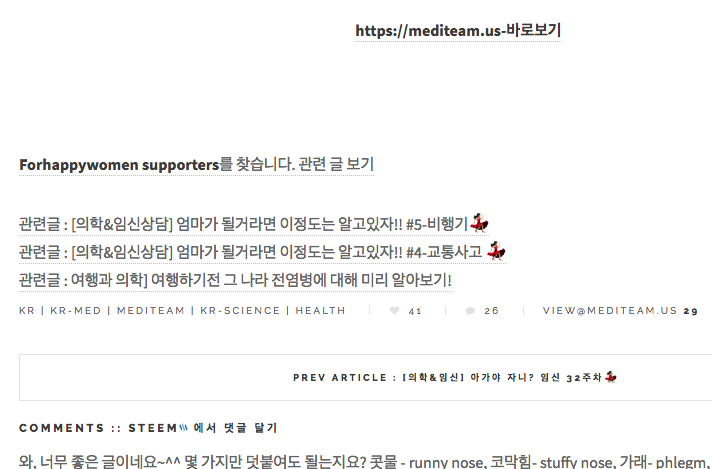
—————–
그러나 이 형태에는 치명적인 문제가 있는데, n개의 문서가 있을 때, 하나의 문서가 추가될 때 아무리 조금 계산해도 n+1 의 cosine similarity를 구해야하며, 전체적으로 갱신하려면 n의 제곱의 해당하는 복잡도가 생기게 된다. 또한 문서가 늘어날수록 IDF에서 단어의 수가 증가하기 때문에 연산이 점차 늘어나게 된다.
그래서 생각해낸 아이디어가 바로 이것. (이건 이미 지난 포스팅의 konlpy 로 하면된다.)

본문의 단어의 빈도를 계산하고,

사이트 내부의 구글신에게 자문을 구하면
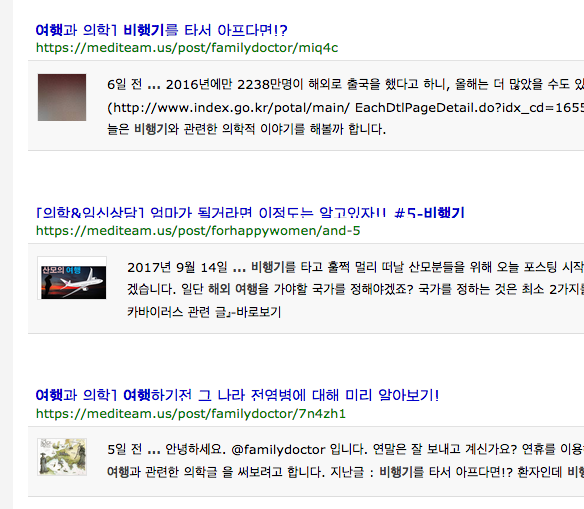
이렇게 글을 보여준다! 다음엔 Selenium을 이용해 위에서 부터 3개정도의 글만 파싱해내면 끝.
그러면 글이 추가될때마다 바로바로 관련글이 검색되면서, 하루에 한번 전체 문서를 갱신해주면 다 최신업데이트가 간단하게 이루어질 수 있다.
그러나 이제 다음 미션은, 한글이 아닌 일본어과 중국어는 어떻게 할 것이냐?
일본에서 만든 형태소 분석기 mecab이라는 라이브러리가 있다. 참고로 이 라이브러리는 nodeJS용으로도 있는 것 같다.
그리고 nodeJS용으로 mecab을 이용해 한글분석기를 구현한 mecab-ya(http://think.golbin.net/post/142517991186) 라는 라이브러리도 있다.
mecab은 일종의 껍데기로 보면 되고, 그 안에 사전(Dictionary)이 있어 언어에 따른 형태소 분석기가 가능하다. 일본에서 만들어서 한국어, 중국어도 가능한 것이다.
그러나 그 과정이 순탄치만은 않았는데 일본어를 테스트하기 위해 mecab 라이브러리를 설치하여 실행하였더니, 다음과 같은 에러가 발생한다.
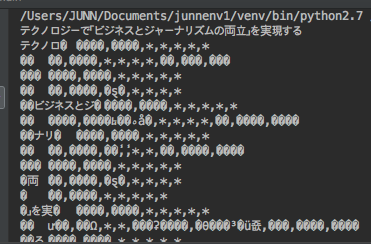
오랜 시간 씨름한 끝에, 이유를 찾았는데 그것은 바로 mecab 라이브러리가 기본적으로 euc-jp 인코딩을 사용하기 때문.
즉 utf-8로 input이 들어가도 출력이 euc-jp로 되어버리니 글자가 깨져서 나와버리는 것이다. 이 출력값을 그대로 파이썬에서 가져오기 때문에 후처리 자체가 불가능 한 것이었다.
이제 원인은 알았고 해결하기 위해 mecab 사전을 utf-8로 바꿔 설치하는 방법을 찾았다. Reference에 있는 mecab-jp 항목들을 보면 된다. (일본어를 읽을 줄 몰라 크롬으로 번역해서 봄)
그러나…하라는대로 해도 맥에서 설치시 에러가 나서 결국 포기.
하지만 이 과정에서 알게 된 것은 우분투 리눅스에서는 이미 utf-8 인코딩을 위해 만들어진 dictionary가 존재한다.
#sudo apt-get install mecab
이 경우 기본 단어장으로 /var/lib/mecab/dic/juman 을 제공한다(경로는 시스템에 따라 달라질 듯)
# mecab 으로 실행한다. 종료는 Ctrl + D

그러나 같은 이유로 깨져서 나온다.
이제 utf-8 단어장을 설치
#sudo apt-get install mecab-ipadic-utf8
출력 과정 중에
update-alternatives: using /var/lib/mecab/dic/ipadic to provide /var/lib/mecab/dic/debian (mecab-dictionary)
라고..기본을 ipadic을 쓴다는 이야기다.
이제는 제대로 출력된다. (종료는 Ctrl +D)
이번엔 그럼 한글 단어장을 설치해보자. 물론 Konlpy를 써도 된다. 어차피 영어는 NTLK를 쓸 예정이니, 한글을 Konlpy도 좋고, mecab도 좋을 것 같다.
한글 단어장만 설치. 패키지로 없어서 직접 진행해야 한다.
# wget https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/mecab-ko-dic-2.0.3-20170922.tar.gz
# tar xvzf ./mecab-ko-dic-2.0.3-20170922.tar.gz
폴더 # ./configure, # make, #sudo make install
중간에 출력문을 보니 이건 또 설치가 다른 곳에 된다 (/usr/local/lib/mecab/dic/mecab-ko-dic)
경로가 엉망진창..잘 모르고 진행하면 이렇게 되는가 싶다.
mecab에서 사전을 바꾸려면 -d 라는 옵션을 붙인다.
# mecab -d /usr/local/lib/mecab/dic/mecab-ko-dic
이렇게 하면 아래와 같이 한글이 잘 분석되어 나온다.
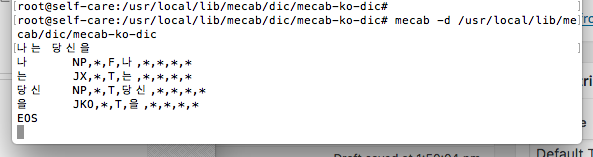
중국어도 사전을 찾으면 되는데, 잘 안찾아진다. 그리고 중국어 문서가 없어서 일단 skip.
다음번에는
(1) 셀레니움을 이용한 검색결과 파싱을 시도해보고,
(2) 문서가 각각 한글/영어/일본어 중 어떤 언어로 이루어졌는지 파악하는 단계
(3) 자주 나오는 단어로 DB를 구성해서, 관련글 검색
하는 과정을 진행해보겠다.
==== 2018.01.09 ====
한글 사전 설치시 mecab의 기본 사전이 한글 사전으로 변할 수 있다.
이 경우 일본사전은 아래 주소
mecab -d /var/lib/mecab/dic/ipadic-utf8
한글 사전은
mecab -d /usr/local/lib/mecab/dic/mecab-ko-dic
이런 주소가 될 수 있겠다.
=====================
Refereces :
1> Mecab-JP:
http://nymemo.com/sakura/258/
https://qiita.com/junpooooow/items/0a7d13addc0acad10606
http://brewinstall.org/Install-nkf-on-Mac-with-Brew/ (euc-jp -> utf8)
http://nymemo.com/sakura/258/
https://qiita.com/junpooooow/items/0a7d13addc0acad10606
2> Mecab-ko :
http://guruble.com/mecab-%ED%95%9C%EA%B8%80-%ED%98%95%ED%83%9C%EC%86%8C-%EB%B6%84%EC%84%9D%EA%B8%B0-%ED%94%8C%EB%9F%AC%EA%B7%B8%EC%9D%B8-%EC%84%A4%EC%B9%98%ED%95%98%EA%B8%B0/
https://github.com/jxpress/pymecab/blob/master/README.md
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #!/usr/bin/python | |
| # -*- coding: utf-8 -*- | |
| from __future__ import print_function | |
| import MeCab | |
| import sys | |
| import string | |
| sentence = "太郎はこの本を二郎を見た女性に渡した。" | |
| try: | |
| print(MeCab.VERSION) | |
| t = MeCab.Tagger (" ".join(sys.argv)) | |
| print(t.parse(sentence)) | |
| m = t.parseToNode(sentence) | |
| while m: | |
| print(m.surface, "\t", m.feature) | |
| m = m.next | |
| print("EOS") | |
| lattice = MeCab.Lattice() | |
| t.parse(lattice) | |
| lattice.set_sentence(sentence) | |
| len = lattice.size() | |
| for i in range(len + 1): | |
| b = lattice.begin_nodes(i) | |
| e = lattice.end_nodes(i) | |
| while b: | |
| print("B[%d] %s\t%s" % (i, b.surface, b.feature)) | |
| b = b.bnext | |
| while e: | |
| print("E[%d] %s\t%s" % (i, e.surface, e.feature)) | |
| e = e.bnext | |
| print("EOS"); | |
| d = t.dictionary_info() | |
| while d: | |
| print("filename: %s" % d.filename) | |
| print("charset: %s" % d.charset) | |
| print("size: %d" % d.size) | |
| print("type: %d" % d.type) | |
| print("lsize: %d" % d.lsize) | |
| print("rsize: %d" % d.rsize) | |
| print("version: %d" % d.version) | |
| d = d.next | |
| except RuntimeError as e: | |
| print("RuntimeError:", e); | |
[입 개발] mecab 설치 with 은전한닢 (mac)
https://bitbucket.org/eunjeon/mecab-ko
http://guruble.com/mecab-%ED%95%9C%EA%B8%80-%ED%98%95%ED%83%9C%EC%86%8C-%EB%B6%84%EC%84%9D%EA%B8%B0-%ED%94%8C%EB%9F%AC%EA%B7%B8%EC%9D%B8-%EC%84%A4%EC%B9%98%ED%95%98%EA%B8%B0/
3> ChromeDriver :
https://chromedriver.storage.googleapis.com/index.html
https://cjh5414.github.io/python-selenium-chrome-exampleanderror/
https://beomi.github.io/2017/02/27/HowToMakeWebCrawler-With-Selenium/
1 comment