‘내가 왜 이걸 하고 있지?’ 시리즈도 막바지입니다.
‘관련글 찾기’ 별거 아닌데, 너무 복잡합니다. 이렇게 꼭 해야하나…다른 좋은 방법 있으면 알려주세요 ㅠ
이번 포스팅은 아래 3개의 이전 포스팅에 이은 내용들입니다.
1) 관련글 찾기 (TF-IDF, konlpy) (https://junn.net/archives/1923)
2) nodeJS와 python 상호 간 통신(using python-shell, synchronize) (https://junn.net/archives/1978)
3) Mecab (Python library)를 이용한 일본어, 한글 형태소 분석 (https://junn.net/archives/category/programming)
Github : https://github.com/junn279/python_examples/blob/master/text_multilang.py
예제는 nodeJS에서 호출되는 함수다 보니까 base64 encoding된 텍스트를 받습니다. 호출하는 방식은 아래와 같습니다. 적절히 변경하시면 됩니다.
# python text_multilang.py ‘encoded_text’
예) python text_multilang.py PHA+PHN0cm9uZz7igJzjgrPjg6zjgrnjg4bjg63jg…
흐름은 다음과 같습니다.
1) 문서가 어떤 언어인지 확인을 한다.
2) 각 언어별로 형태소 분석을 한다.
1) 언어 확인
문서가 어떤 언어로 쓰여있는지 확인하기 위해 python의 langdetect 라는 라이브러리를 사용합니다.

유니코드로 넣지 않으면 에러가 발생합니다. 참고로 위 소스는 sys.setdefaultencoding(‘UTF8’) 를 통해 UTF8을 기준으로 했습니다. 따라서 UTF8 세팅 이후에 외국어의 경우는 unicode() 함수 처리 또는 u” 를 통해 변환해줘야 합니다.
위의 text1,2,3,4는 에러가 안납니다. 그러나 한글과 일본어의 경우 u, 또는 unicode()를 써서 유니코드로 변환해주지 않으면 에러가 생기게 됩니다.
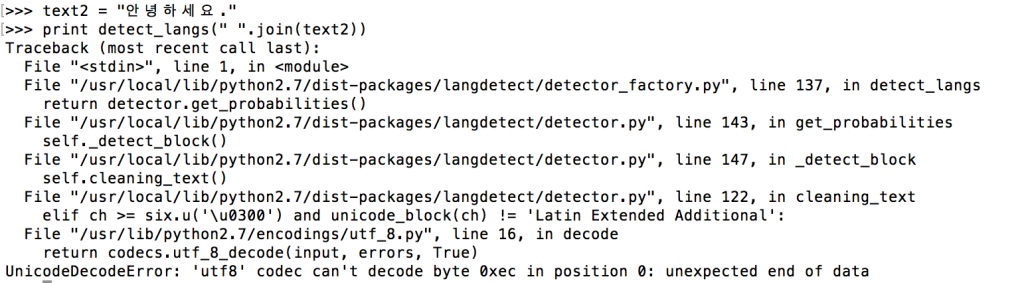
detect_langs 함수는 그 문서가 쓰여진 언어의 확률 분포를 보여줍니다. [ja:0.999999944135] 이런식으로요. 보통 가장 높은 확률의 언어를 바로 받아오면 되기 때문에 detect 함수를 씁니다.

바로 이렇게 갈 수 있습니다.
2) 언어별 형태소 분석
한글 : 이전 포스팅 참조 (https://junn.net/archives/1978) – Konlpy를 이용합니다.
영어 : NLTK를 사용합니다.
한글과 일본어를 제외하면 일단 영어로 판단하고 다 nltk로 넘겼습니다. 여기서도 변수값이 unicode로 들어가야 에러가 안납니다. 영어 문서에 들어있는 다른 언어들 때문입니다.
pos_tag를 통해 형태소를 구하고, NN(명사), NNS(복수명사)만 분리해내었습니다.

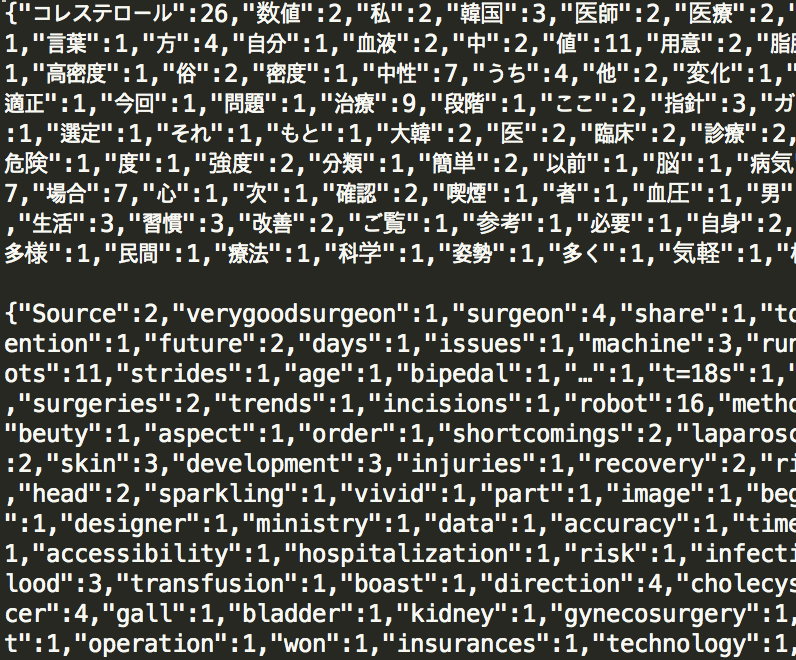
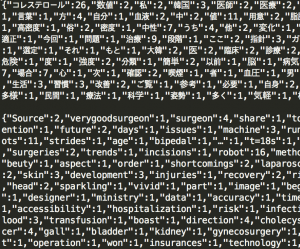
후처리를 통해 확인한 값은 아래와 같습니다.

일본어 : MeCab을 사용합니다. (참조 : https://junn.net/archives/2034)

utf8 으로 구성된 단어장을 이용합니다. 69번째 줄은 명사 이면서, 숫자는 아니고, 가타카나로 읽을 수 있는 단어만 찾게 하는 코드입니다. 결과는 아래와 같습니다. 배열을 json으로 바꿔서 추후 후처리 하면 아래와 같이 빈도수를 계산할 수 있습니다.

다음 포스팅에서는 실제로 이렇게 찾은 토큰들을 통해 Selenium으로 구글 검색 결과를 가져오는 것을 보여드리겠습니다. 처음 제대로 써봤는데 신기한 부분들이 많았습니다. (현재 Mediteam.us의 한글로 적힌 글에 붙어있는 관련글 보기는 이미 selenium을 통해 구해진 검색 결과를 이용하고 있습니다. crontab에 명령을 안붙여놔서 최신 글들은 반영이 안되어있을 수 있습니다.)
References:
https://pypi.python.org/pypi/natto-py
https://taku910.github.io/mecaba
http://www.nltk.org/
https://pypi.python.org/pypi/langdetect