홍콩과기대 김성훈 교수님의 강의가 정말 어마어마하다.
처음에 텐서플로우가 처음나왔을때 이게 뭔 소리지? 했던 부분들이 완벽히 이해되는 강좌. 이해를 하고 나니 훨씬 사용이 쉬워진 느낌.
궁극적으로는 softmax기법을 이용해서 5~6차원의 데이터를 classification하는 부분으로 진행해야하는데, 일단 오늘은 2차원에서만 테스트를 진행
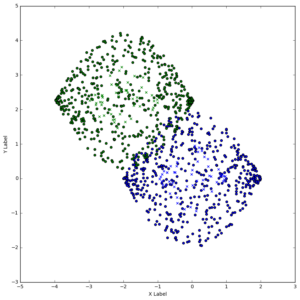
다음과 같은 분포에서
hypothesis = tf.nn.softmax(tf.matmul(X, W)) cost = tf.reduce_mean(tf.reduce_sum(-Y*tf.log(hypothesis), reduction_indices=1))
기본적인 softmax로 진행했고, accuracy를 구했더니
correct_prediction = tf.equal(tf.argmax(Y,1),tf.argmax(hypothesis,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
print session.run(tf.argmax(Y,1),feed_dict={Y:ty3})
print session.run(tf.argmax(hypothesis,1),feed_dict={X:tm4})
print session.run(accuracy, feed_dict={X:tm4,Y:ty3})
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1] [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1] 0.94
94% 결과를 보였다. 위에서 잘못나온 좌표를 그래프랑 비교해보니, 사실 그렇게 (사람이 보기에) 헷갈릴만한 좌표는 아니었는데, 그래서 직접시행해보니
print session.run(hypothesis,feed_dict={X:[[1,-0.43,0.47]]})
[[ 0.48978248 0.51021749]]print session.run(hypothesis,feed_dict={X:[[1,-0.4,0.4]]})
[[ 0.50540406 0.49459586]]

3개의 그룹에서는 57%로 출력. 생각보다 낮게나온다.
그래서 학습을 2000번에서 4000번으로 증가시켜봤다. 그랬더니 73%
6000번때는 85%, 10000번에는 90%까지 증가함을 확인.
다음번엔 3차원 자료를 이용해볼 예정