들어가며
이 글은 2017년 3월에 작성된 내용으로, 딥러닝 모델, 알고리즘의 발전 속도를 생각해보면 2년간의 차이는 상당히 크다고 볼 수 있다. 그러나 개인적으로 음성에 대한 딥러닝 연구는 이미지 처리에 비해 잘 와닿지 않아, Mask R-CNN의 번역처럼, 그 기초를 다지는데 도움이 되지 않을까하여 번역을 시작해본다. (2019년 3월 24일)
- 이 글은 저자(Dhruv Parthasarathy)의 허락을 받아 번역하여 게시하는 글입니다.
- 원문은 https://blog.athelas.com/paper-1-baidus-deep-voice-675a323705df 에서 확인할 수 있습니다.
- 원작자를 ‘나‘로 표기하였습니다, ‘최근‘이라는 단어는 2017년 5년을 기준이므로 지금(2019년)과의 차이가 있을 수 있음을 미리 밝힙니다.
서문
이 포스팅은 최근에 출판된 머신러닝/인공지능 논문에서, 내가 생각하기에 특히나 중요하다고 생각하는 것들 중에 첫번째로 작성하는 글이다. 이 내용에 포함되어있는 아이디어들은 꽤나 직관적(intuitive)인 것으로, 나는 내가 글을 적어나가는 방식을 통해 이러한 직관적인 부분과 소통할 수 있을 것으로 생각한다. 첫번째 내용으로 Baidu에서 발표한 딥러닝을 TTS (text to speech) 시스템에 적용시킨 Deep Voice 에 대한 내용을 다룰 것이다.

최근 Andrew Ng이 이끄는 Baidu AI팀은 한편의 인상깊은 페이퍼를 올렸는데, 이는 딥러닝을 기반으로 한 Text-to-speech 시스템에 대한 내용이었다. 이 바이두 팀의 페이퍼를 통해 생성 가능한 음성 중 하나의 예시는 아래와 같다.
바이두의 TTS 결과. 출처: http://research.baidu.com/deep-voice-production-quality-text-speech-system-constructed-entirely-deep-neural-networks/ (역자주: 링크가 깨진듯 하다)
확실히, 바이두의 결과는 맥OS에서 제공하는 TTS 시스템의 목소리와 비교하면 자연스럽고, 더 인간적이다. (역자주: Terminal에서 say -v “Yuna” “안녕. 나는 유나라고해” 라고 쳐보자) 그러나 ‘주의할 점’ 이란 문구를 하나 붙여야 하는데, 그것은 바이두의 샘플은 누군가가 저 문장을 직접 말해서, 즉 질적으로 좋은 문장을 통해 학습할 기회가 있었다는 점이다. 또한 바이두 샘플은 주파수 및 음성의 길이 정보 또한 갖고 있었다.
그러나, 단지 결과물의 질적인 측면을 넘어서, 이 페이퍼가 ‘음성’을 다루는 이 세계에서 새로운 지평을 열은 몇가지의 키포인트들이 존재한다.
1. Deep Voice는 Text-to-speech 시스템의 모든 부분에서 Deep learning을 사용하였다.
기존의 연구들은 Text에서 speech로 가는 pipeline에 각기 다른 부분들을 딥러닝을 적용하였으나, 그 어떤 기존 연구도 이 페이퍼처럼 모든 주요한 컴포넌트들을 신경망으로 대체한 적이 없었다.
2. 매우 적은 feature engineering 만이 필요하여, 다른 데이터셋에 적용하기가 쉽다.
전통적인 TTS pipeline과 달리, 저자들은 딥러닝을 통해 방대한 양의 feature processing 과정을 피할 수 있었다. 이는 Deep Voice가 다른 영역(domain)의 문제들에 더 일반화할 수 있고, 적용가능하게 한다. 실제적으로, 페이퍼의 저자들이 아래에 적은 바와 같이 전통적인 시스템에서 수 주가 걸렸을 일을 몇 시간만에 재조정이 가능하다고 하였다.
기존의 TTS 시스템에서 재훈련(retraining)은 수일에서 수 주간의 튜닝이 필요하지만, Deep Voice는 단 몇 시간 만의 수동 작업으로 모델을 훈련시키는 데 걸리는 시간을 단축 할 수 있다.
3. 음성 생성 시스템에 사용되던 기존의 최고의 기술(the state of the art) 모다 극단적으로(extremely) 빠르다.
이 연구의 저자들은 DeepMind사에서 발표한 human-like audio synthesis를 구현한 WaveNet보다 400배 이상 빠르다라고 주장한다. 구체적으로 아래와 같이 적었다:
우리는 바로 음성 생성이 가능한 (production-ready) 시스템을 만드는데 집중하였는데, 이를 위해서 우리의 모델이 실시간으로 작동해야했다. DeepVoice는 1초를 더 작게 나눈 단위에서도 합성이 가능하며, 또는 합성 속도 및 오디오 품질 사이에서 조정 가능한 트레이드 오프(역자주: 음질을 높이면 합성 속도가 늦어질 수 있음을 의미) 를 제공합니다. 반면에 WaveNet을 이용한 결과물들은 1초의 음성을 합성하기 위해 수분의 시간이 필요했습니다.
배경 지식
확실히, 흥분할만한 내용들이 많다! 그러나 이 모든 작업이 어떻게 이루어질까? 포스팅의 뒷부분에서는 Deep Voice의 각기 다른 부분들을 훑어볼 것이다. 아래의 강좌는 아래의 내용들을 따라오는데 도움을 주는 내용이다.
- Adam Coates’ lectuer (3:49부터 볼 것) Baidu에서 Speech 영역이 딥러닝을 적용한 것에 대한 내용이다. Dr. Coates는 Deep Voice 저자 중 한 명으로, 이전에 스탠포드에서 Andrew Ng과 함께 일했다.
이 자료를 보았으면, 이제 Deep Voice가 어떻게 작동하는지 볼 차례다. 포스팅의 뒷부분은 아래의 구조에 맞추어 작성되었다:
- 첫번째, 우리는 Deep Voice 가 어떻게 문장들을 이용하여 음성 생성을 위해 변환시키는지 넓게 바라볼 것이다. 즉, 추론 파이프라인(inference pipeline; 역자주: 음성 추론에 이르는 파이프라인, 즉 ‘음성 합성 과정’) 을 살펴보는 것이다.
- 그리고나서 이 파이프라인을 부분부분 나누어 각각에 대해 이해해 볼 것이다.
- 다음 포스팅에서는 실제로 이 각각의 부분들이 어떻게 학습되는지, 실제 학습용 데이터와 레이블은 어떻게 이루어졌는지 볼 것이다.
- 마지막으로, 다른 포스팅에서 이 각각의 컴포넌트들을 종합한 딥러닝 아키텍쳐에 대해 살펴보겠다.
음성 합성 과정 파이프라인 (The Inference Pipeline) – 텍스트를 음성으로 변환하기
넓은 시야에서 Deep Voice가 간단한 문장을 우리가 들을 수 있는 소리로 변환하는 과정을 살펴보자.
파이프라인은 아래의 구조를 갖는다.
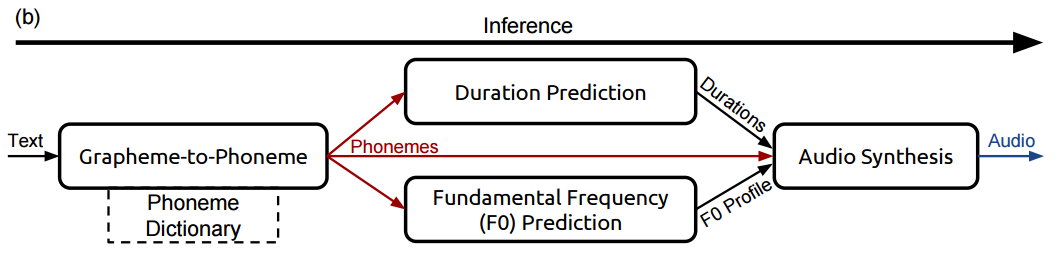
첫번째 단계: Grapheme (text;철자)을 Phoneme (음소) 으로 바꾸기
영어와 같은 언어는 알파벳 자체가 음소가 되지 않는다는 특징을 갖는다. 예를 들어, “ough”를 접미어로 갖는 다음의 단어들에서 각각의 소리가 어떻게 나는지 생각해 보자. (예시는 여기에서 찾았다)
- though (Go에서 “o”와 같음)
- through (too 에서 “oo”와 같음)
- cough (offerx 에서 “off”와 같음)
- rough (suffer에서 “uff”와 같음)
역자주: 언어학에 대한 지식이 부족하여, 우리나라말이 이와 같은지 잘 모르겠지만, 이와 비슷한 상황에 에를 들자면, “국물” 에서 종성의 “ㄱ”은 “궁물”와 같이 “ㅇ”로 발음된다. 우리나라말도 결국 텍스트를 들리는대로 라벨링하는 과정을 거쳐야 할 것이다
같은 철자라도 꽤나 분명하게 다른 발음을 갖는 다는 것을 알 수 있다. 만약 우리의 TTS 시스템이 입력된 ‘문자대로’ 발음하게 된다면 “rough”와 “through”의 발음이 다르게 되어야한다는 점을 구현하는 것과 같은 피할 수 없는 문제가 생기게 된다. 따라서 우리는 발음에 대해 더 정확한 정보를 보여주는 약가는 다른 표현 방법(representation)이 필요하다.
이것은 정확히 phoneme(음소)가 필요한 이유이다. Phoneme은 우리가 만들어내는 음성의 다른 단위가 된다. 그 음소들을 합쳐서 우리는 거의 모든 단어의 발음을 표현해낼 수 있다. 아래는 단어를 음소 단위로 나누어 적은 예시다. (예시는 여기에서 참조)
- White Room – [W, AY1, T, ., R, UW1, M, .]
- Crossroads – [K, R, AO1, S, R, OW2, D, Z, .]
역자주: 예를 들어 우리나라말로는 “광복절에 태극기” – [광,복,쩌,래,.,태,그,끼] 등으로 변환할 수 있겠다. 재밌는 것은 Tacotron 2를 이용한 예제를 보면, 개개인 별로 나타나는 발음상의 특징들-‘태극기’ 발음에서도 누군가는 ‘태그끼’가 아니라 ‘태극끼’ 처럼 들릴 수 도 있는-을 살릴 수 있다는 점이다. Attention이 그런 부분들을 살리는 주요한 요소일 것 같다.
위의 분석에서 음소 옆에 붙은 숫자 1,2(예: AY1) 등은 반드시 표현되어야 하는 발음의 강세의 위치를 나타낸다. (역자주: 우리나라말에서도 필요한지는 잘 모르겠다) 구두점(.)은 빈 공간을 나타낸다.
정리하면, Deep Voice의 첫번째 스탭은, 모든 문장을 각각의 음소들로 간단하게 변환하는 것이다. 예를 들면 이것 처럼 말이다.
우리의 문장
Deep Voice는 다음의 입력값과 출력값을 이용할 것이다.
- Input – “It was early spring”
- Output – [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
다음 포스팅에서 어떻게 학습시키는지 알아볼 것이다.
두번째 단계, 파트 1: 길이 예측(duration prediction)
음소들을 얻었으면 우리는 말하는동안 이 음소들이 얼만큼의 발음 시간을 갖는지 예측할 필요가 있다. 이것은 같은 음소라도 문맥에 따라 길거나 짧은 길이를 갖을 수 있다는 점에서 흥미로운 문제다. 다음 예제들에서 “AHN” 음소의 주변 음소에 따른 변화를 생각해보자.
- Unforgettable
- Fun
명백히 “AHN” 발음은 두번쨰 단어보다 첫번째 단어에서 더 길게 발음해야하며 우리는 정확히 이렇게 시스템에 학습을 시켜야 한다. 결국, 모든 음소들에 대해 얼마나 길게 소리낼 것인가(몇초) 예측헤야 한다.
우리의 문장
이 단계에서 우리의 문장이(It was early spring) 어떻게 구현되는지 보자.
- Input – [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
- Output – [IH1 (0.1s), T (0.05s), . (0.01s), … ]
두번째 단계, 파트 2: 기본 주파수 예측(fundamental frequency prediction)
우리는 가능하면 사람다운 소리를 만들기 위해 또한 각각의 음소에서 음조(톤;tone)과 억양(intonation)를 예측하는 것이 필요하다. 이는 중국어와 같이 음조와 강세만으로 같은 소리가 완전히 다른 의미를 갖는 중국어와 같은 언어에서 특히나 중요하다. 각 음소에서 기본주파수를 예측하는 것은 이런 부분에서 우리를 도와준다. 기본주파수는 음소가 어떻게 발음되어야 하는지에 대해 시스템에 대략의 음색(pitch)와 음조를 알려주는 역할을 한다.
추가적으로, 몇몇의 음소들은 전혀 발성과정을 통해 이루어지지 않는다. 다시말해서, 성대의 발성없이 나는 소리를 의미한다.
예를 들어 “ssss”, “zzzz” 두 소리의 경우, 전자는 성대의 진동 없이 나는 소리(무성음;unvoiced)이며, 후자 성대의 진동이 필요한(유성음;voiced) 소리이다.
기본주파수 예측 단계에서는 이러한 점을 고려하여 어떤 음소가 유성음인지 무성음인지를 고려해야 한다.
우리의 문장
이 단계에서 우리의 문장이(It was early spring) 어떻게 구현되는지 보자.
- Input – [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
- Output – [IH1 (140hz), T (142hz), . (Not voiced), … ]
세번째 단계: 음성 합성

마지막 단계는 음소, 길이 정보, 주파수들을 이용하여 음성을 출력하는 것이다. Deep Voice는 이 단계를 DeepMind에서 발표한 WaveNet을 변형한 버전을 이용하여 구현하였다.
나는 독자들에게 WaveNet의 구조를 이해하기 위해 WaveNet의 오리지널 포스팅을 읽어보는 것을 추천한다.

이론적으로 WaveNet은 모든 종류의 소리들, 다른 엑센트와 감정, 숨소리 등등의 여러 기본적인 사람의 음성의 요소들을 갖는 음성(raw waveform)을 생성할 수 있다.
이 포스팅에서 Baidu의 팀은 WaveNet을 고주파수 입력값에 더 적합하게 변형시켰다. 그렇함으로써 WaveNet의 경우 수초 가량의 음성생성에 수분이 소요되는데, Baidu의 변형된 WaveNet은 단지 1초도 안되는 시간 단위만 필요로 할 뿐이다.
서두에 적었듯이 저자들은 다음과 같이 말한다.
DeepVoice는 1초를 더 작게 나눈 단위에서도 합성이 가능하며, 또는 합성 속도 및 오디오 품질 사이에서 조정 가능한 트레이드 오프(역자주: 음질을 높이면 합성 속도가 늦어질 수 있음을 의미) 를 제공합니다. 반면에 WaveNet을 이용한 결과물들은 1초의 음성을 합성하기 위해 수분의 시간이 필요했습니다.
우리의 문장
마지막 단계에서 우리의 문장은 다음과 같다.
- Input – [IH1 (140hz, 0.5s), T (142hz, 0.1s), . (Not voiced, 0.2s), W (140hz, 0.3s),…]
- Output – 바로 아래의 결과물이다.
출처: http://research.baidu.com/deep-voice-production-quality-text-speech-system-constructed-entirely-deep-neural-networks/
요약
이것이 전부다. 이 3 스탭을 통해 우리는 Deep Voice가 어떻게 간단한 텍스트 조각들로 그 음성을 표현하게 되는지 볼 수 있었다. 각각의 스탭을 요약하면 아래와 같다.
- 텍스트를 음소로 변환 “It was early spring”
- [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
- 음소의 길이와 주파수를 예측
- [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .] -> [IH1 (140hz, 0.5s), T (142hz, 0.1s), . (Not voiced, 0.2s), W (140hz, 0.3s),…]
- 음소와 길이, 주파수를 하나로 합쳐 음성으로 합성
- [IH1 (140hz, 0.5s), T (142hz, 0.1s), . (Not voiced, 0.2s), W (140hz, 0.3s),…] -> Audio
그러나 어떠한 방식으로 실제 Deep Voice가 위의 과정들을 수행하는 것일까? 어떻게 Deep Voice는 이러한 목표를 달성하기 위해 Deep Learning을 활용하는 것일까?
다음 포스팅에서, 우리는 Deep Voice의 각각의 부분들이 어떻게 학습되고 우리에게 신경망 뒤에 숨어있는 직관(intuition)을 줄 수 있는지 알아볼 것이다.
번역 후기
머리속에 그리고 있는 음성 연구를 위해서는 필연적으로 Attention mechanism을 이해하는 가야하는데, 아직 갈 길이 먼 것 같습니다. 기초도 한걸음 부터라고, 2017년의 포스팅이 이미 많은 시간이 지났지만 또 이렇게 시작하는 것이 좋을 것 같았습니다. 빠른 시일내로 두번째 번역 포스팅도 올리도록 하겠습니다.
1 comment